I was recently made aware of an interesting issue, which appears to be a pretty fundamental property of the departure time-based traffic shaping that is used by many BPF-based data planes, such as in the Cilium Bandwidth Manager. It’s one of those things that seem really obvious in hindsight, but that no one thought about beforehand (apparently; or at least I didn’t). So I thought I’d write up an analysis here to explain what’s going on and why it is a problem.
Note that I’m not trying to pick on Cilium in particular here. While this issue appeared as a bug report for Cilium, their implementation is just one instance of the same approach. More details below.
What is departure time-based traffic shaping?
The departure time-based shaping idea was first presented by a bunch of Googlers at the 2020 Netdevconf. The use case is to shape the traffic coming out of a single container (or pod, for Kubernetes-style deployments); basically so you can set a max bandwidth for the pod, and the CNI will ensure that this is enforced.
The “old-fashioned” way of doing this kind of multi-class shaping (where a “class” is “everything that comes from a single pod”) is by using an HTB hierarchy, where each traffic class gets its own token bucket, and its own qdisc instance to manage the queue. However, this only works when all the traffic actually hits that bucket, and to ensure this happens, the HTB tree is generally installed as the root qdisc on the outgoing interface.
As noted in the Netdevconf presentation linked above, the problem with having a
single HTB tree on the outgoing interface, is that this means every packet
enqueue and dequeue will hold the global qdisc lock. On a multicore system, this
leads to a lot of lock contention when multiple CPUs send traffic
simultaneously, which hurts performance. The mq qdisc can get around this by
having separate qdiscs attached to each hardware queue, allowing each CPU to get
its own qdisc instance. But doing this with HTB doesn’t work, because you’d have
to install separate HTB trees on each hardware queue. Doing so means you’ll also
have separate token buckets on each hardware queue, so you are no longer
enforcing a single global bandwidth limit1.
The solution from the presentation above is to rely on timestamps to shape the traffic: run a BPF program that processes traffic as it exits the pod, and in that BPF program, shape the traffic by setting a timestamp for each packet. The algorithm to do this is short enough that it fits into a single slide, in pseudo-code format at least (slide 7 in the presentation linked above):
aggregate_state = state[classify(skb)] # classify packet into flow aggregate
delay_ns = skb->len * NS_PER_SEC / aggregate_state->rate_limit_bps
next_tstamp = &aggregate_state->next_tstamp
if *next_tstamp <= now:
*next_tstamp = now + delay_ns # racy, not an issue, same ballpark value expected
return TC_ACT_OK
if *next_tstamp - skb->tstamp >= (int64_t)DROP_HORIZON: # 2s
return TC_ACT_SHOT
if *next_tstamp > skb->tstamp:
skb->tstamp = *next_tstamp # rate-limit
__sync_fetch_and_add(next_tstamp, delay_ns)
return TC_ACT_OK
This still has synchronisation across CPU cores (the __sync_fetch_and_add()
call near the end), but this only requires a single atomic instruction instead
of holding the qdisc lock for the entire enqueue/dequeue operation. Once the
timestamp is set, the fq qdisc will manage the queueing of the packets without
any further synchronisation across cores: each packet will simply be delayed
until the time encoded in its timestamp. So you can install separate fq
instances on each hardware queue, and avoid the lock contention of the root
qdisc lock. Pretty neat!
Hints of a problem
The scheme presented above is (presumably) running in production at Google. However, more interestingly, as mentioned in the introduction it is also what powers the Cilium Bandwidth Manager, and as the Cilium developers also found it to be a significant improvement over HTB. In fact, the Cilium implementation is almost verbatim the same as the pseudocode in the listing above, so this gives us an open source implementation for Kubernetes to study.
The first hint of a problem with the EDT scheme came in the form of an issue on the Cilium bug tracker. In it, Anton Ippolitov had tried running the Flent RRUL test in a container with the Cilium bandwidth manager turned on, and, well, the results were not great:
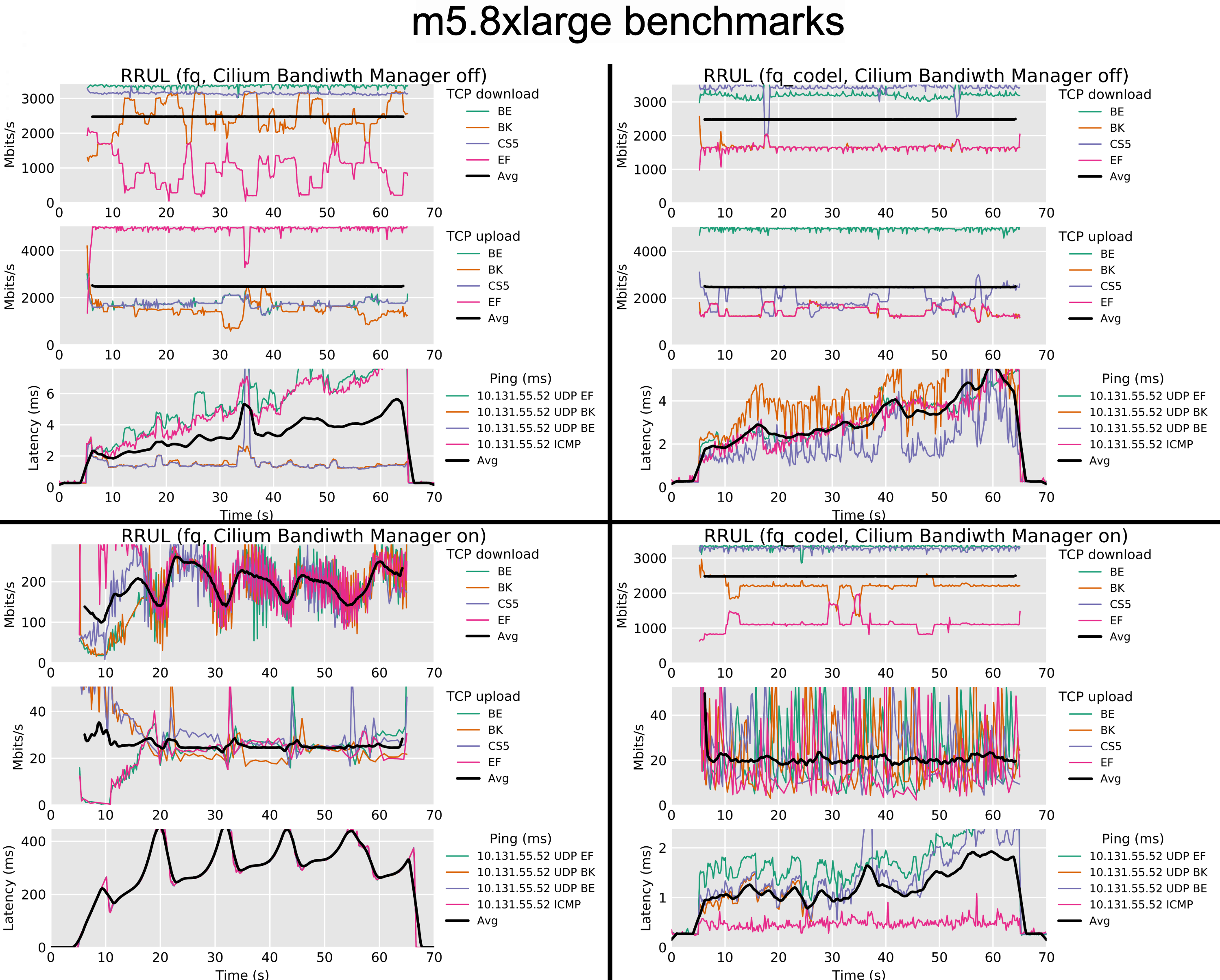
RRUL test results
These tests show the results of running the RRUL test inside a container with the Cilium bandwidth manager enabled, and either the fq or fq_codel qdiscs installed on the host-side physical interface. The 'BE', 'BK', 'CS5' and 'EF' labels refer to different DiffServ markings that the test applies to each flow. However, nothing in this test reacts to those markings, so it's safe to just ignore them.
The bottom-left graph is the one to watch here: latency spikes above 400ms while
the bulk TCP flows are running. Classic bufferbloat! And only with fq as the
qdisc; with fq_codel there is very little extra latency under load (as is
normally the case with fq_codel).
The FIFO in the EDT
Starting with the bottom-left graph, what could be the cause of the latency spikes under load? To find the answer, we have to go back and examine how the EDT shaper works. The timestamps applied to each packet determine the earliest time a packet will be transmitted at (hence the name, Earliest Departure Time scheduling). We can visualise this as the packets having “space” between them when they are inserted into the queue:

EDT vs FIFO queueing
In a regular FIFO, packets are queued one after the other and go out at line rate. With EDT, each packet has a timestamp that it will be dequeued at. One can think of this as the packets having 'space' between them, which can be used to achieve a particular shaping rate. In this example, packets are queued with 1 ms of delay from between them.
In the shaping scheme we are discussing here, the actual EDT queueing is
performed by the fq qdisc, which will put each flow into its own queue, but
still delay the packets based on their timestamps. And because the timestamps
are always assigned sequentially for all packets from a given pod (cf. the
algorithm above), in effect we end up with a virtual FIFO queue with gaps
between the packets, even if the packets are actually queued up in different
per-flow queues. In effect something like this:

Multi-flow EDT queueing
Even if packets are enqueued in multiple per-flow queues, because of the global timestamp assignment, we will end up with a virtual FIFO queue across all packets coming out of the same pod.
This indeed matches the results we see above: the bufferbloat is there simply
because there is, in fact, a giant (virtual) FIFO queue that all the traffic
goes into! And it’s not surprising either that fq_codel shows much better
results, as that just ignores the timestamps and does its usual thing2.
As far as I can tell, this “virtual FIFO” behaviour is pretty fundamental to this kind of EDT-based queueing: because the timestamps are assigned ahead of time, before the packets are actually put into a queue, the virtual time of the scheduler will advance for each packet, and you can’t assign an earlier timestamp to a later packet even if you wanted to prioritise it. Because if you do so, the shaper will no longer enforce the configured bandwidth (as the previously enqueued packets are still waiting in the queue).
Update: It’s worth noting that the queueing delay seen here is introduced
regardless of whether the packets actually end up queued. Because the shaper
advances the next packet timestamp at the point where the packet exits the
container, even if it is then subsequently dropped (e.g., because it exceeds the
drop horizon or the per-flow packet limit in fq), the next packet will still
be delayed, so you still get the (virtual) queueing delay.
Mitigating factors
So if the EDT shaping is really just a giant FIFO, why are both the presentations linked above showing such great results? Surely either the Google folks first proposing this scheme, or the Cilium people implementing it in their CNI would have noticed this?
Well, the answer turns out to be “TSQ backpressure”. Daniel Borkmann jumped in to the discussion on the issue above3 and suggested that the results were probably not using the eBPF host routing feature of the Cilium CNI4. And indeed this was the case; Anton later returned with a new test with eBPF host routing enabled:
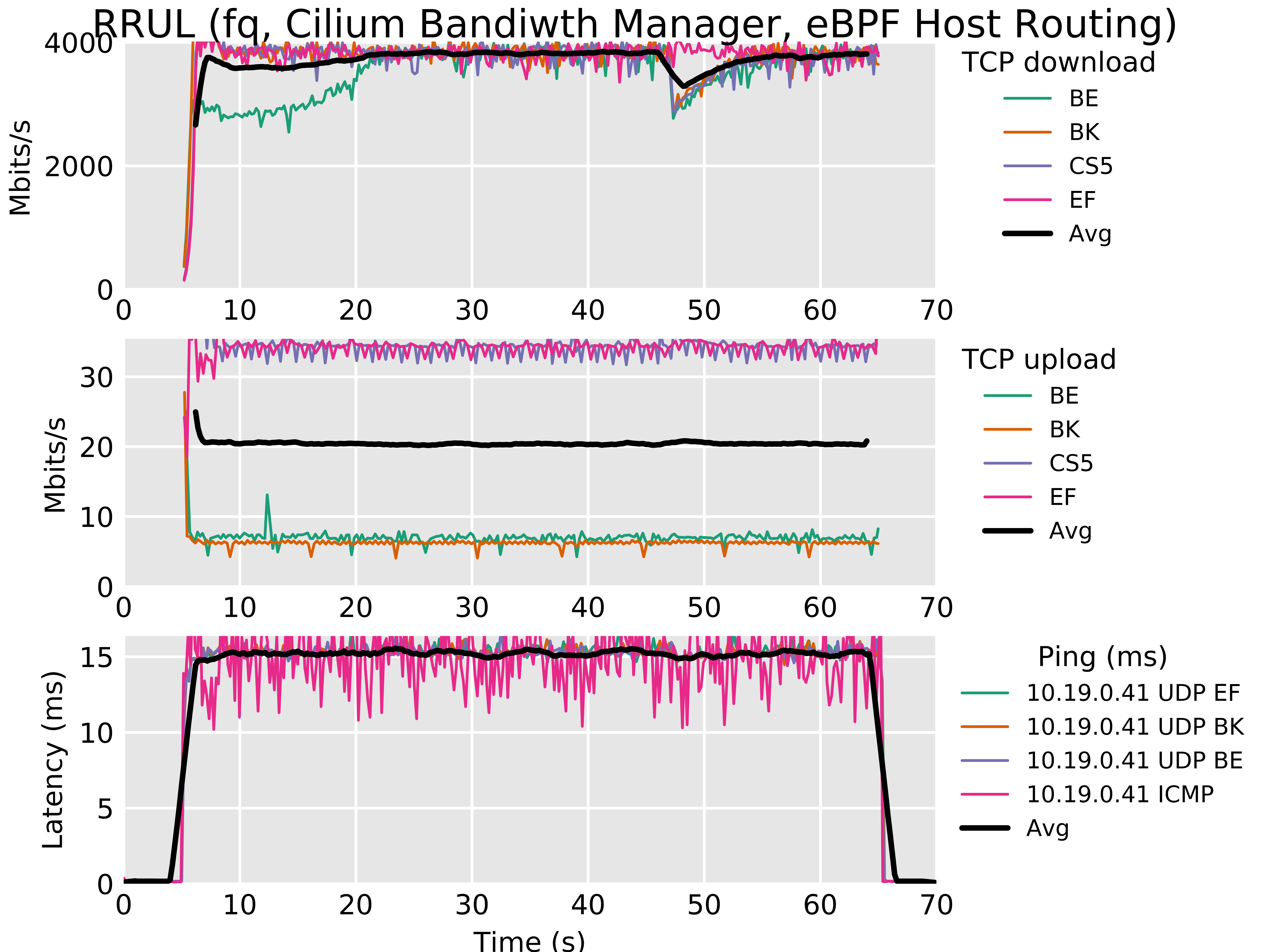
The RRUL test with eBPF host routing enabled
Using eBPF host routing means the networking stack will not *orphan* the SKB as it traverses the host stack. This in turn means that the TCP stack tracks the packet all the way until it has left the physical host interface, and accounts for it in its TSQ calculations. Which provides proper backpressure, removing most of the added latency.
This looks much better! What we see here is TSQ kicking in, limiting the amount of data each flow will queue up in the buffers in the stack, leading to only 15 ms of added latency during the upload test. In absolute numbers, that is probably bearable, and it is quite believable that this behaviour is better than that which we can get from HTB with a global lock. But it’s still one or two orders of magnitude above the idle latency (as seen from the first and last five seconds of the graph), and my expectation is that the absolute added latency will scale proportionally with the number of flows.
Another interesting feature here is the unfairness between the flows in the upload direction (which is where the shaper is). I don’t have a good explanation for why exactly this happens; but the reason it stays so pronounced throughout the test is most likely that there are no drops due to queue overflow that causes flows to oscillate around their fair share of the bandwidth. Instead, once the unfairness sets in, it is maintained by the per-flow limits imposed by TSQ5.
Takeaways
I personally found this issue to be quite fascinating. Seeing those graphs, the issue becomes quite obvious, and yet I had watched both the original Netdevconf presentation and the follow-up by Cilium, and hadn’t thought about EDT scheduling as a FIFO before. I’m hoping reading this write-up has been as enlightening (and fascinating) for you!
To summarise, I think there are a few things we can take away from this:
While the EDT-based traffic shaping does work, it relies crucially on backpressure within the network stack. In particular, this means that it works for TCP, but only if the forwarding path out to the NIC does not orphan the SKBs. Without this backpressure it is just a giant virtual FIFO with the associated terrible bufferbloat.
Even with correct backpressure, the EDT-based shaping is still essentially a FIFO, so there is no flow queueing (and the associated sparse flow prioritisation), and the latency will be a function of the number of backlogged flows (since the TSQ limits are per-flow). Also, it looks like there are some pretty serious issues with fairness among flows.
Even with the flaws we have covered here, it is quite believable that this is still a better solution for bandwidth shaping than an HTB tree with a global lock. But we really need a better solution to the global qdisc lock issue as we continue to scale across cores. I have some hope that the eBPF qdisc can be helpful for implementing queueing systems that can selectively synchronise across instances while running independently attached to multiple hardware queues.
You could get around this by also separately ensuring that all traffic from the same pod hits the same hardware queue; but that is far from straight forward, and often not even desirable because it would constrain which CPUs a container can run on (hardware queues are normally tied to CPUs).
[return]The only mysterious thing about the
[return]fq_codelresults is that the shaper is working at all in this scenario. This turns out to be because of the ‘drop horizon’ seen in the code above; the timestamps will simply exceed this occasionally leading to drops that cause TCP to back off. See the issue discussion for more details.I would really recommend reading the whole issue thread, there are more details that I’m leaving out here.
[return]Daniel also updated the Cilium documentation to mention that the bandwidth manager should be used with the BPF host routing feature of Cilium.
[return]Yeah, this is a bit handwavy. If you have a better explanation, please feel free to chime in here, or send me an email!
[return]
